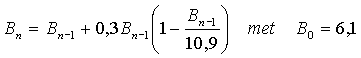| Bevolkingsgroei | ||||
| De wereldbevolking neemt nog steeds toe, maar groeit niet in ieder werelddeel even hard. De figuur hieronder laat zien hoe men in 1984 verwachtte dat de bevolking zich zou ontwikkelen. | ||||
 |
||||
| In 2000 bedroeg de wereldbevolking 6,1 miljard mensen. | ||||
| 4p | 9. | Onderzoek of dit aantal in overeenstemming is met de figuur hierboven | ||
|
|
||||
Onlangs stelde iemand het
volgende model op om een ruwe schatting van de toekomstige
wereldbevolking te maken:
Hierin is Bn de wereldbevolking in miljarden mensen en n
het aantal eenheden van 10 jaar na 2000. Dus B0 is de
wereldbevolking in 2000, B1 de wereldbevolking in 2010,
enzovoort. Volgens dit model zal de wereldbevolking op de lange duur een grenswaarde bereiken. |
||||
| 4p | 10. | Onderzoek, of de wereldbevolking volgens dit model in 2050 minder dan 10% van deze grenswaarde verwijderd zal zijn. | ||
|
|
||||
| Bij dit model kan een webgrafiek gemaakt worden. Zie de figuur hieronder. | ||||
 |
||||
| 3p | 11. | Teken de eerste drie stappen (dus van B0 tot en met B3) van de webgrafiek in deze figuur. Licht je werkwijze toe. | ||
| Of het model de toekomstige ontwikkeling redelijk beschrijft, moeten we nog afwachten. Wel kunnen we controleren of het model in overeenstemming is met de ontwikkeling vóór 2000. Zo is te berekenen hoe groot volgens de formule voor Bn de wereldbevolking in 1990 was. | ||||
| 4p | 12. | Voer deze berekening uit. | ||
|
|
||||
| Orkanen | |||||
| Orkanen zijn zeer zware stormen. Ze
ontstaan boven de oceaan. Wanneer ze de kust bereiken, kunnen ze enorme
schade aanrichten. De zuidoostkust van de Verenigde Staten wordt hier
vrijwel elk jaar door geteisterd. In het gebied rond Tampa Bay in
Florida zijn gedurende een lange periode alle zware stormen
geregistreerd. Het staafdiagram hieronder is hierop gebaseerd. Je kunt bijvoorbeeld zien dat het in deze periode drie keer is voorgekomen dat het na een zware storm 51/2 tot 6 jaar duurde tot de volgende zware storm. |
|||||
 |
|||||
| 4p | 13 | Laat door een berekening zien dat er ruim 110 jaar zit tussen de eerste en de laatste zware storm waar de figuur hierboven betrekking op heeft. | |||
|
|
|||||
| Om bewoners van bedreigde
kustgebieden tijdig te kunnen evacueren, doet het National Hurricane
Center om de zes uur een voorspelling over de plaats waar de orkaan zich
24 uur later zal bevinden. Ook voorspelt het waar de orkaan 48 uur later
en 72 uur later zal zijn. Achteraf wordt van iedere voorspelling
nagegaan hoe groot de afstand is tussen de voorspelde plaats en de
werkelijke plaats van de orkaan. Zo vindt men bij iedere voorspelling een
afwijking. Deze afwijkingen worden gemeten in zeemijlen (1 zeemijl =
1853 meter) Elk jaar wordt het gemiddelde berekend van de afwijkingen van de 24-uurs-voorspellingen en ook van de 48-uurs- en 72-uurs-voorspellingen. Deze gemiddelden zijn in de volgende figuur weergegeven. |
|||||
 |
|||||
| Het aantal voorspellingen verschilt sterk van jaar tot jaar. In 1970 is er slechts 3 keer een 72-uurs voorspelling gedaan, in 1971 wel 118 keer. Ook de nauwkeurigheid van de voorspellingen wisselt sterk. Iemand meent zich te herinneren dat in 1970 of 1971 bij één van de 72-uurs-voorspellingen de afwijking wel 900 zeemijl was. | |||||
| 4p | 14. | Leg uit dat deze afwijking van 900 zeemijl niet in 1970 kan zijn voorgekomen. | |||
|
|
|||||
| In de figuur hierboven is te
zien dat de 24-uurs-voorspellingen in de loop van de tijd steeds 'beter'
worden. Om dit te bestuderen worden twee modellen opgesteld. Het volgende eenvoudige model stemt redelijk overeen met de werkelijkheid:
Hierbij is D de gemiddelde afwijking in zeemijlen en t de tijd in jaren vanaf 1970. Op de lange termijn voldoet dit model niet meer omdat de gemiddelde afwijking volgens dit eenvoudige model dan nul of zelfs negatief zou worden. Daarom is ook een ander model opgesteld dat aan dit bezwaar tegemoet komt:
|
|||||
| 4p | 15. | Onderzoek hoeveel de uitkomsten van deze modellen maximaal van elkaar verschillen in de periode 1970 - 2010 | |||
|
|
|||||
Men wil ook voor de
49-uurs-voorspelllingen een model opstellen van de vorm:
De opstellers stellen als voorwaarde dat de uitkomsten van dit
model altijd groter moeten zijn dan de uitkomsten van het
overeenkomstige model voor de 24-uurs-voorspellingen. |
|||||
| 4p | 16. | Welke persoon heeft gelijk? Licht je antwoord toe. | |||
|
|
|||||
| Vierkeuzevragen | |||||||||||||
| Bij vierkeuzevragen staan bij elke vraag vier mogelijke antwoorden: A, B, C en D. Slechts één daarvan is juist. Een kandidaat kan één van de vier antwoorden kiezen of de vraag onbeantwoord laten. Bij keuze van het juiste antwoord wordt 1 punt toegekend, in alle andere gevallen 0 punten. Als een kandidaat absoluut niet weet welk antwoord juist is en welke antwoorden onjuist zijn, doet hij er daarom verstandig aan om toch een antwoord te geven. Dit leidt tot gokgedrag. | |||||||||||||
| Daarom is ook wel eens geopperd om bij een onjuist antwoord strafpunten te geven. Een kandidaat heeft dan twee keuzes: niets invullen levert 0 punten op; wel iets invullen levert 1 punt op bij een juist antwoord en -0,5 punt (0,5 strafpunt) bij een onjuist antwoord. | |||||||||||||
| 3p | 17. | Bereken de verwachtingswaarde van de score per vraag bij dit strafpunten systeem als een kandidaat gokt. | |||||||||||
|
|
|||||||||||||
| Subjectieve kansen We kijken nu naar een andere manier van toetsen met vierkeuzevragen. Hierbij hoeft de kandidaat niet meer één antwoord te kiezen. In plaats daarvan vraagt men de kandidaat achter elk van de vier mogelijke antwoorden A, B, C en D de subjectieve kans op te schrijven. Een kandidaat die bijvoorbeeld noteert pA = 0,2; pB = 0,8; pC = 0; pD = 0 geeft daarmee aan dat hij er vrij zeker van is dat B juist is, maar dat A ook nog zou kunnen, en dat C en D volgens hem zeker fout zijn. De opgeschreven getallen pA, pB, pC, en pD mogen natuurlijk niet negatief zijn en moeten bij elkaar opgeteld 1 zijn. Bij iedere vraag wordt een score berekend die aangeeft 'hoe
dicht je bij het juiste antwoord zit'.
Voor de gevallen waarbij A, B of D het juiste antwoord is, gelden
soortgelijke formules. Bij een bepaalde vraag is het juiste antwoord B. Een kandidaat die
niet helemaal zeker van zijn zaak is, noteert bij deze vraag de
subjectieve kansen: |
|||||||||||||
| 4p | 18. | Bereken de score voor deze kandidaat bij deze vraag. | |||||||||||
|
|
|||||||||||||
| Stel dat bij een andere vraag C het juiste antwoord is. Een kandidaat haalt bij deze vraag de minimale score. | |||||||||||||
| 3p | 19. | Welke subjectieve kansen kan de kandidaat opgeschreven hebben achter de antwoorden A, B, C en D? Vermeld alle mogelijkheden. | |||||||||||
|
|
|||||||||||||
| Een kandidaat moet een vraag beantwoorden maar heeft geen idee welk antwoord juist is en welke antwoorden onjuist zijn. Er zijn heel veel mogelijkheden voor de kandidaat om die vraag te beantwoorden: | |||||||||||||
|
|||||||||||||
| Er zijn nog veel meer
mogelijkheden om de vraag te beantwoorden. We kijken echter alleen naar de
bovengenoemde vier mogelijkheden. De score bij mogelijkheid IV is hoger dan de verwachte score bij mogelijkheid I. Mogelijkheid IV is daarmee een 'verstandiger' strategie dan mogelijkheid I. |
|||||||||||||
| 7p | 20. | Onderzoek welke van de mogelijkheden II, III en IV de meest verstandige strategie is. | |||||||||||
|
|
|||||||||||||
| We vergelijken de antwoorden
van twee personen op een vierkeuzevraag Tim snapt niets van de vraag en besluit bij elk antwoord 0,25 in te vullen. Tom weet zeker dat de antwoorden B en D onjuist zijn. Zijn antwoord op deze vraag zal van de vorm zijn: |
|||||||||||||
|
|||||||||||||
| Hierbij is a een getal
tussen 0 en 1 (eventueel 0 of 1).
Stel dat antwoord C juist is. Of Tom bij deze vraag een hogere score haalt dan Tim hangt af van de gekozen waarde van a. |
|||||||||||||
| 4p | 21. | Bereken voor welke waarden van a geldt dat Tom bij deze vraag een hogere score haalt dan Tim. | |||||||||||
|
|
|||||||||||||
| OPLOSSINGEN | |
| Het officiële (maar soms beknoptere) correctievoorschrift kun je HIER vinden. Vooral handig voor de onderverdeling van de punten. | |
| 1. | aflezen: bij score
65 zit ongeveer 78%. Dus 22% heeft score hoger dan 65. Dat zijn ongeveer 0,22 • 2255 = 496 kandidaten. |
| 2. | Aflezen uit de
grafiek bij 25% en 50% en 75% resp. 42 en 25 en 63 punten. Uit de tekst halen we dat 0 punten de laagste en 88 punten de hoogste score is. Dat geeft de volgende boxplot:  |
| 3. | normalcdf(0, 44.5 ,
63.8 , X) = 0,06 Y1 = normalcdf(0, 44.5 , 63.8 , X) en Y2 = 0,06 Levert via intersect (bijv. met window [10,20] × [0 , 0.1]) dat X = 12,4 Dat is dus kleiner dan die van de hele steekproef want die was 14,7 |
| 4. | H0:
p = 0,29 (p = kans op onvoldoende; ze deden het dus
evengoed) H1: p < 0,29 (de A&B-leerlingen deden het beter en hebben dus kleinere kans op een onvoldoende) De meting was 33 van de 546 Overschrijdingskans is P(X ≤ 33) = binomcdf(546, 0.29, 33) ≈ 0 Dat is duidelijk veel kleiner dan 0,05, dus H0 moet verworpen worden. Conclusie: de bewering van de docent wordt NIET bevestigd. |
| 5. | Er zijn gemiddeld 180 banden in voorraad (lineair tussen 0 en 360), dus dat kost 180 • 180 = 32400 |
| 6. | leveringskosten per
band: 3500/360 = 9,72 voorraadkosten per band: 32400/4500 = 7,20 inkoopskosten per band: 30 opbrengst per band: 70 Winst = 70 - 30 - 9,72 - 7,20 = 23,08 |
| 7. | Er zijn gemiddeld
0,5x banden in voorraad dus dat kost in totaal 180 • 0,5x
= 90x leveringskosten per band: 3500/x voorraadkosten per band: 90x voor 4500 banden is 90x/4500 = 0,02x per band inkoopskosten per band: 30 opbrengst per band: 70 Winst = 70 - 30 - 0,02x - 3500/x = 40 - 3500/x - 0,02x |
| 8. | W = 40 - 3500 • x-1
- 0,02x
⇒ W' =
-1 • -3500 • x-2 - 0,02 = 3500 • x-2
- 0,02 W'= 0 ⇒ 3500/x² = 0,02 ⇒ x2 = 3500/0,02 = 175000 ⇒ x = √175000 = 418,33 x = 418 levert gemiddelde kosten per band 23,266794... x = 419 levert gemiddelde kosten per band 23,266778.. Dus bij bestelgrootte 419 is de winst per band maximaal.. |
| 9. | We lezen bij 2000 de
aantallen af in miljoenen: Oceanië ≈ 10, Noord-Amerika ≈ 200, Sovjet-Unie ≈ 200, Europa ≈ 450, Latijns-Amerika ≈ 550, Afrika ≈ 880, Verre Oosten ≈ 1450 en West- en Zuid-Azië ≈ 2100 Samen is dat 10840 miljoen en dat is 10,8 miljard. Dat lijkt NIET in overeenstemming, maar het is wel erg onnauwkeurig aflezen... |
| 10. | Invoeren in de GR
(MODE SEQ) nmin = 0 u(n) = u(n-1) + 0,3 • u(n - 1) • (1 - u(n-1)/10,9) u(nmin) = 6,1 Dan in de tabel kijken levert als grenswaarde 10,9 miljard (vanaf ongeveer n= 28) In 2050 (n = 5) zijn er 9,42 miljard Dat scheelt 1,48 miljard en dat is 1,48/10,9 • 100% = 13,6% In 2050 is de bevolking dus meer dan 10% van de grenswaarde verwijderd. |
| 11. | Tekening: Begin bij B0 = 6,1 op de x-as. Ga omhoog tot de gekromde grafiek, daarna opzij naar de lijn y = x Bij dit punt hoort B1 op de x-as. Ga weer omhoog naar de gekromde grafiek, en weer opzij naar y = x, enz. |
| 12. | Stel de bevolking in
1990 gelijk aan x, dan geldt: 6,1 = x + 0,3x • (1 - x/10,9) 6,1 = x + 0,3x - 0,3x • x/10,9 ⇒ 6,1 = 1,3x - 0,0275x2 ⇒ 0,0275x2 - 1,3x + 6,1 = 0 ABC-formule levert nu x = 41,99 V x = 5,28 en dat laatste is het juiste antwoord. (met de GR Y1 = 6,1 en Y2 = x + 0,3x • (1 - x/10,9) en dan intersect kan ook natuurlijk) In 1990 was de wereldbevolking 5,28 miljard. |
| 13. | Neem de
klassenmiddens als benadering (dus 0,25 - 0,75 - ...) Dan is de totale tijd in het staafdiagram: 12 • 0,25 + 14 • 0,75 + 10 • 1,25 + .... + 1 • 10,75 = 106,75 Dat is ongeveer 110 jaar. |
| 14. | In 1970 waren 3
waarnemingen die gemiddeld 250 opleverden. Als er één al 900 is, levert dat al een gemiddelde van 300, dus met de andere twee erbij wordt dat alleen maar groter en kan nooit 250 worden. |
| 15. | Voer beide formules
in bij Y1 en Y2 Plot vervolgens Y3 = Y1 - Y2 en kijk waar Y3 maximaal (of minimaal) is. (domein is [0,50]) Neem bijv voor Y3 window [0 , 50] × [-20 , 10] dan vind je de volgende grafiek:  Grootste afwijking is te vinden via calc - minimum en is bij x = 37,06 en y = -15,91 De twee modellen verschillen op dit domein dus maximaal 15,91 zeemijl van elkaar |
| 16. | Neem bijv. b
= 53, a = 1 en t =
1 Dan is Doud = 118,576 en Dnieuw = 53,984 Dus is niet aan de voorwaarde voldaan. Kortom: persoon I heeft niet gelijk. Als één van beiden gelijk moet hebben dan moet dat dus wel persoon II zijn. |
| 17. | P(1 punt) = 0,25 en
P(-0,5 punt) = 0,75 De verwachtingswaarde is dan 1 • 0,25 + -0,5 • 0,75 = -0,125 |
||||||||
| 18. | Voor het juiste
antwoord B geldt de formule: score = 1 - (pA2
+ (1 - pB)2 + pC2+
pD2) Invullen geeft score = 1 - (0,22 + 0,32 + 02 + 0,12) = 1 - 0,14 = 0,86 |
||||||||
| 19. | Er zijn drie
mogelijkheden:
|
||||||||
| 20. | Twee antwoorden, dan
is de kans op de goede 0,5 en op geen goede dus ook 0,5 Met de goede erbij levert het 1 - (0,52 + 0,52) = 0,5 punt op Zonder de goede levert het 1 - (0,52 + 0,52 + 12) = - 0,5 punt op De verwachtingswaarde van het aantal punten is 0,5 • 0,5 + 0,5 • -0,5 = 0 Drie antwoorden, dan is de kans op de goede
erbij 0,75 en de kans op niet de goede 0,25 |
| 21. | Tim scoort 0,25. Tom scoort 1 - (a2 + 02 + (1 - (1 - a))2 + 02) = 1 - a2 - a2 = 1 - 2a2 Ze scoren evenveel als 1 - 2a2 = 0,25 ⇒ 2a2 = 0,75 ⇒ a2 = 0,375 ⇒ a = √0,375 = 0,6123... Tom scoort meer als a kleiner is dan dit getal, dus voor 0 < a < √0,375 |