|
© h.hofstede (h.hofstede@hogeland.nl) |
||||||||||||||||||
|
|
||||||||||||||||||
| Berekeningen aan de normale verdeling. | ||||||||||||||||||
| Zo. Nu wordt het de hoogste tijd
om eens wat serieuze berekeningen aan klokvormen te gaan verrichten.
Kijk, dat gedoe met die vuistregels is wel aardig natuurlijk om een
beetje een idee van de normale verdeling te krijgen, maar je hebt er
verder niet echt veel aan. In praktijk komt het natuurlijk niet vaak
voor dat je precies 1 of 2 standaardafwijkingen van het gemiddelde af
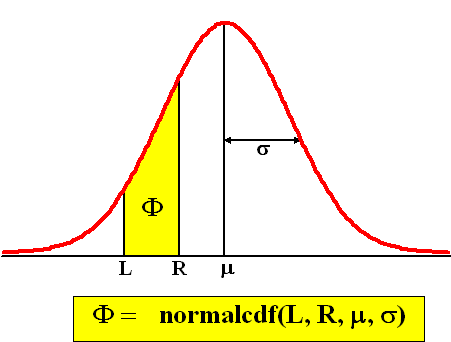
bent. Dat zou wel héél toevallig zijn, toch? Gelukkig heeft onze TI-83 een knop om tussen twee willekeurige x-waarden uit te rekenen wat de oppervlakte onder de normale verdeling is. Het volgende plaatje vat goed samen hoe het werkt: |
||||||||||||||||||
|
|
||||||||||||||||||
| • De functie normalcdf vind
je bij 2nd - Distr. • L is de linkergrens (kleinste x) en R is de rechtergrens (grootste x). • Tussen de letters in staat steeds zo'n dikke komma. • De oppervlakte is een getal tussen 0 en 1 en wordt aangegeven met de letter Φ. |
||||||||||||||||||
|
||||||||||||||||||
| Twee Speciale gevallen. | ||||||||||||||||||
| De twee speciale gevallen kun je hieronder zien in een klokvorm: | ||||||||||||||||||
|
|
||||||||||||||||||
| In deze gevallen loopt het gevraagde gebied helemaal door naar één kant, en is er maar één echte grens af te lezen. Wat moet je in zo'n geval doen? Ach, waarschijnlijk had je het zelf al wel geraden: Je kiest die onbekende grens gewoon ver genoeg weg. Doe maar gewoon een belachelijk groot (positief of negatief) getal, zodat je zeker weet dat wat er dan nog buiten die grens valt zeker te verwaarlozen is. | ||||||||||||||||||
|
||||||||||||||||||
| DISCREET en CONTINU | ||||||||||||||||||
| Bedenk goed, dat de normale
verdeling een continue verdeling is. Dat betekent dat alle
meetwaarden kunnen voorkomen. De berekeningen gaan met een
vloeiende klokvorm, en niet met de horten en stoten van een histogram.
Dat betekent bijvoorbeeld dat de normale verdeling geen verschil kent
tussen "KLEINER" en "KLEINER-OF-GELIJK". Kijk maar: |
||||||||||||||||||
|
|
||||||||||||||||||
| P(X < 80) is de gele oppervlakte
in de linkerfiguur. P(X ≤ 80) is de gele oppervlakte PLUS DE BLAUWE LIJN in de rechterfiguur. Maar die blauwe lijn is oneindig dun, dus die heeft oppervlakte NUL. Beide figuren geven daarom dezelfde oppervlakte, en dus dezelfde kans. HEERLIJK! Je hoeft lekker nergens op te letten. |
||||||||||||||||||
|
|
||||||||||||||||||
| OPGAVEN | ||||||||||||||||||
| 1. | Ik heb de laatste
tijd heel hard getraind, en de tijd die ik hardloop over 10 kilometer is
nu normaal verdeeld met een gemiddelde van 45 minuten en een
standaardafwijking van 2 minuten. Hoe groot is de kans dat mijn volgende 10 kilometer meer dan 43 minuten maar minder dan 44 minuten gaat duren? |
|||||||||||||||||
| 2. | De lengte van
maïsplanten op een akker is op een bepaald moment normaal verdeeld met
een gemiddelde van 170 cm en een standaardafwijking van 22 cm. Hoe groot is de kans dat een willekeurige maïsplant van deze akker dan tussen de 150 en 160 óf tussen de 175 en 180 cm lang is? |
|||||||||||||||||
| 3. | Bij de winkel BLOKKER verkopen
ze twee soorten tuinfakkels. Soort A en soort B. Ze hebben de brandtijd daarvan getest. Het bleek dat de brandtijd van soort A normaal verdeeld was met een gemiddelde van 45 uur en een standaardafwijking van 8 uur. Voor soort B gold een gemiddelde brandtijd van 42 uur met een standaardafwijking van 12 uur. Ik wil graag tuinfakkels die 2 dagen lang non-stop branden. Dus hun brandtijd moet minstens 48 uur zijn. Welke soort kan ik het beste kopen? |
|||||||||||||||||
| 4. | Een groep vrienden
doet elke maand in de kroeg mee met een pubquizz. In maart was de gemiddelde score van alle teams normaal verdeeld met een gemiddelde van 70,6 punten en een standaardafwijking van 6,5 punten. In april was de gemiddelde score van alle teams normaal verdeeld met een gemiddelde van 62,2 punten en een standaardafwijking van 8,2 punten. Je mag in deze opgave doen alsof elk aantal punten mogelijk is, dus niet alleen gehele aantallen. |
|||||||||||||||||
| a. | Hoeveel procent van de deelnemende teams zal in maart meer dan 74 punten hebben gescoord? | |||||||||||||||||
| b. | De vriendengroep
scoorde in maart 72 punten en in april 68 punten. Alhoewel dat in april een lagere score was vinden zij toch dat zij in april beter gescoord hebben dan in maart. Ben je dat met hen eens? |
|||||||||||||||||
| c. | Van de teams die aan
beide quizzen meededen heeft 8% beide keren 65 of lager
gescoord. Laat met een berekening zien dat dat hoger is dan je aan de hand van de gegevens zou verwachten en probeer daar een verklaring voor te geven. |
|||||||||||||||||
| 5. | Op een grote kippenboerderij verzamelt men 's morgens alle gelegde eieren om die te gaan verkopen. De eieren worden ingedeeld en gesorteerd in vier klassen, met elk een verschillende opbrengst per ei: | |||||||||||||||||
|
||||||||||||||||||
| Het gewicht van de
eieren van de kippen op deze boerderij is normaal verdeeld met een
gemiddelde van 66 gram en een standaardafwijking van 10 gram. Hoeveel zal een partij van 5000 eieren naar verwachting opbrengen? |
||||||||||||||||||
|
|
||||||||||||||||||
| © h.hofstede (h.hofstede@hogeland.nl) | ||||||||||||||||||