|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| We hebben al gezien
dat spreidingsmaten aangeven hoe ver de gemeten getallen uit elkaar
liggen. Daarvoor hebben we al de spreidingsbreedte de
kwartielafstand en de gemiddelde deviatie behandeld. Maar er is nog een
andere, veel meer gebruikte maat voor de spreiding, en dat is de
standaardafwijking
(of ook wel de
standaarddeviatie). De letter die we daarvoor gebruiken is σ. De berekening daarvan is vrij ingewikkeld, en die hoef je niet helmaal te kennen. Ik noem hem toch. Het recept ervoor is als volgt: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Oh ja; waarschijnlijk had je het
al wel verzonnen hoop ik: als je te maken hebt met een klassenindeling,
dan doe je weer alsof alle metingen in een klasse gelijk zijn aan het
klassenmidden.
Wat heeft dat voor zin? |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
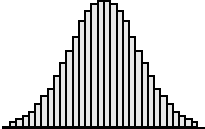
| Het blijkt in praktijk dat histogrammen er
vaak ongeveer zo uitzien als hiernaast. Veel metingen zijn ongeveer
gelijk aan het gemiddelde en steeds minder metingen zitten verder van
het midden af. Dit histogram heet de normale verdeling en de "breedte" daarvan blijkt makkelijk te beschrijven met de standaarddeviatie. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
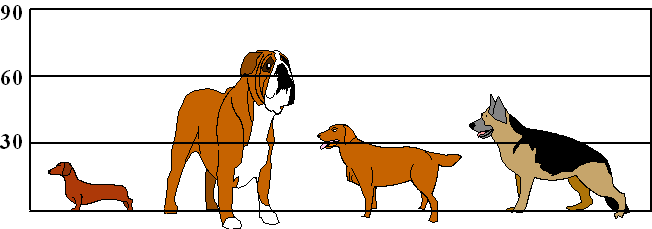
| Voorbeeldberekening. Vier hondenliefhebbers vergelijken de hoogte van hun honden: |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
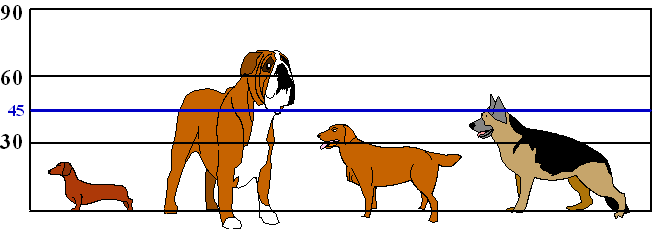
| Ze meten achtereenvolgens de
hoogtes 19 cm, 70 cm, 39 cm en 55 cm. De gemiddelde hoogte is dan 45 cm, en dat geeft de blauwe lijn hieronder aan |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
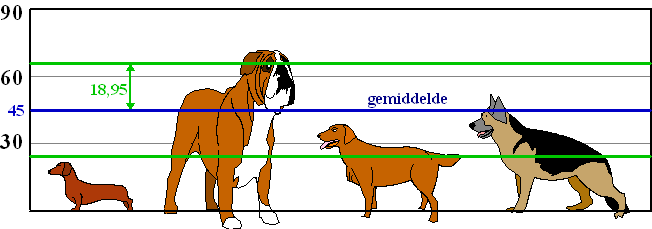
| De afwijkingen van de vier honden
ten opzichte van dat gemiddelde zijn 26 cm, 25 cm, 6 cm en 10 cm. De kwadraten daarvan zijn 676, 625, 36 en 100 Het gemiddelde van deze vier kwadraten is (676 + 625 + 36 + 100)/4 = 359,25 De wortel daarvan is √359,25 ≈ 18,95 cm. Hieronder kun je zien wat die spreiding van 18,95 cm ten opzichte van het gemiddelde van 45 cm betekent. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De beide groene lijnen liggen op afstand
18,95
cm vanaf het gemiddelde. Je ziet dat de laatste twee honden minder dan een standaarddeviatie van het midden af zitten. In de tabel hiernaast is nog eens schematisch te zien hoe de berekening van de standaarddeviatie in zijn werk is gegaan. |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Wat stelt het ongeveer voor? | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
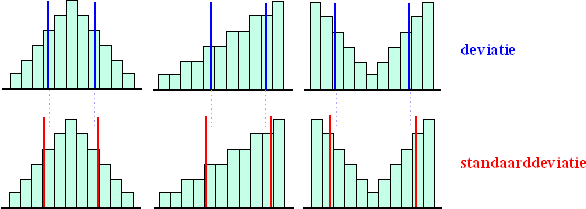
| Hieronder zijn voor een aantal histogrammen in dezelfde figuur de standaarddeviatie en de gemiddelde deviatie als afstand vanaf het gemiddelde gegeven. De blauwe en rode lijnen hieronder geven steeds de plaats van gemiddelde-plus-deviatie/standaarddeviatie en gemiddelde-min-deviatie/standaarddeviatie. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Je ziet dat het allemaal niet spectaculair veel verschilt van elkaar. De standaarddeviatie bestrijkt steeds een iets breder deel van het histogram dan de "gewone"deviatie. Dat komt natuurlijk omdat die buitenste meetwaarden wat zwaarder meetellen. | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
Met de GR Nou, dat gaat precies zo als de berekeningen van het gemiddelde en de mediaan en de kwartielen. Voer de frequentieverdeling in in je TI via STAT - EDIT Bedenk wel dat je bij een klassenindeling de klassenmiddens moet gebruiken in L1. Gebruik daarna STAT - CALC - 1: 1-Var Stats ( L1 , L2 ) waarbij in L1 de meetwaarden (evt klassenmiddens) staan en in L2 de frequenties (of procenten). L1 en L2 vind je boven de knoppen 1 en 2 (dus 2nd gebruiken). In het lijstje dat je dan voor je neus krijgt is
σx
de standaarddeviatie. |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Zoals je ziet komen in L1 de
klassenmiddens (als dat nodig is) rechts zie je dat de standaarddeviatie gelijk is aan 8,978..... |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
De standaarddeviatie van een rij
losse getallen. Natuurlijk kun je ook van een rij "losse" getallen de standaarddeviatie berekenen. Volgens bovenstaande methode zou je de getallen in L1 moeten zetten allemaal met frequentie 1 in L2, immers elk getal komt één keer voor. Maar je rekenmachine kan dat sneller.... Als je je getallen in L1 zet, en dan eenvoudig gebruikt STAT - CALC - 1-Var-Stats (L1) dan neemt je rekenmachine automatisch alle frequenties gelijk aan 1. Dat scheelt weer een boel enen in vullen...... |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OPGAVEN | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
© h.hofstede (h.hofstede@hogeland.nl) |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||