|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
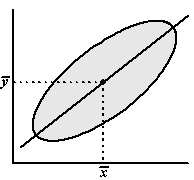
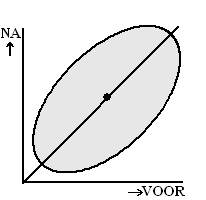
| Laten we beginnen met een
geweldig onderzoek: een puntenwolk met zóveel punten dat we ze niet eens
allemaal kunnen tekenen, maar aangeven als één grijze ellips. Hiernaast staat de centrale lijn van deze ellips getekend. Dat is niet de regressielijn, maar de symmetrieas van de ellips. Als je een regressielijn (van y op x) gaat tekenen dan ga je ervan uit dat x de oorzaak is, en y het gevolg. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
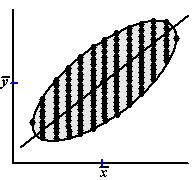
| Dan kijk je dus bij één bepaalde
x welke y-waarden er allemaal gemeten zijn, en ga je de
lijn zó kiezen dat de som van de residuen in het kwadraat minimaal is.
Bij zo'n volledig symmetrische figuur als de ellips hiernaast zal het je vast niet verbazen dat die ideale regressielijn gaat door de midden van de verticale stippenlijnen hiernaast (er zijn er natuurlijk nog veel meer dan hier getekend) |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
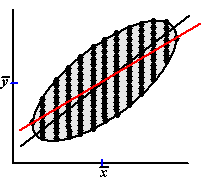
De regressielijn van y op x is
de rode lijn hiernaast. Hij gaat ook door het centrale punt, maar loopt
vlakker dan de centrale lijn (dat is aan de uiteinden het duidelijkst te
zien: de regressielijn gaat door die twee uiterste punten waar de
raaklijn aan de ellips verticaal is, terwijl de centrale lijn door de
toppen van de ellips gaat).
|
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
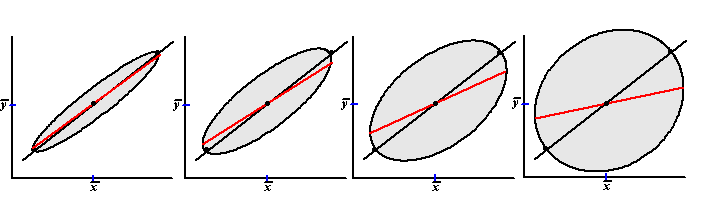
| Dit laatste effect heet het
regressie-effect. En hoe kleiner de correlatiecoëfficiënt r is, des te groter is dit regressie-effect. Kijk maar naar de volgende plaatjes: |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Van links naar rechts wordt de
correlatiecoëfficiënt r steeds kleiner maar het regressie-effect steeds
groter (dat is immers het verschil tussen de rode en de zwarte lijn). Het VOOR-NA onderzoek! Dit regressie-effect kom je het vaakst tegen bij een zogenaamd voor-na onderzoek. Een bepaalde groep proefpersonen wordt getest op een eigenschap voor een behandeling en na een behandeling. Bijvoorbeeld: we onderzoeken de wiskundecijfers VOOR en NA een examentraining, of we meten de bloeddruk VOOR en NA het gebruiken van een medicijn, of noem maar op. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
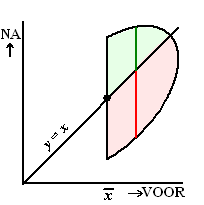
| Als je dan het resultaat van de eerste test
op de x-as zet, en dat van de tweede test op de y-as, dan
kun je een puntenwolk van je metingen maken. Laten we eens aannemen dat
er geen effect van de behandeling is. Dus dat de resultaten (gemiddelde
en spreiding) VOOR en NA gewoon gelijk zijn. Natuurlijk zal niet elk
proefpersoon precies dezelfde resultaten hebben, maar gemiddeld en qua
spreiding de hele groep wél. De centrale lijn zal de lijn y =
x zijn. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Maar bekijk nu eens alleen degenen met een
eerste score hoger dan het gemiddelde. Dat geeft de afgesneden ellips
hiernaast. De mensen in het rode gebied zullen op de tweede test een
lagere score halen, de mensen in het groene gebied een hogere score. Maar dat rode gebied is veel groter. Dat betekent dat de kans dat zo iemand bij de tweede test een lagere score haalt dan op de eerste test groter is dan een hogere score. Het rode verticale lijntje is langer dan het groene! |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| En andersom zullen mensen die de eerste score onder het gemiddelde zaten bij de tweede score juist vaker hoger scoren. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sir Francis Galton kwam dit effect het eerst tegen toen hij de lengtes van vaders en zonen met elkaar vergeleek. Daarbij viel op dat erg lange vaders gemiddeld minder lange zonen kregen, en korte vaders juist gemiddeld langere zonen dan zijzelf. Hij noemde het effect "regression towards mediocrity". |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Je kunt het ook op de volgende twee manieren zien: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De regressie-valkuil | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Ik beweer dat ik een nieuwe
rekenmethode heb ontwikkeld, die vooral geschikt is voor
basisschoolleerlingen die zwak in rekenen zijn. Ik ga daarmee naar een
aantal basisscholen en vraag hen om deze methode één maand te laten
gebruiken door hun zwakste rekenleerlingen. Vooraf doen we een test wie
de zwaksten zijn, en na een maand doen we weer een test om te kijken of
mijn methode werkt. Wedden dat er verbetering is??? Ik kan dan natuurlijk trots beweren wat voor geweldige methode ik heb ontworpen. Maar als je iets weet van het regressie-effect, dan trap je daar natuurlijk niet zomaar in. Als je de methode alleen toepast op degenen met in het begin de laagste rekenscores dan zal dat een tweede keer statistisch gezien altijd een hogere score geven, ook al gebeurt er niets! |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Toch wordt vaak trots opgeschept over zo'n methode, of zelfs beweerd dat
"wetenschappelijk is aangetoond" dat zo'n methode helpt. Je reinste
onzin natuurlijk! Gewoon het regressie-effect. (De enige echt wetenschappelijke manier zou zijn om de zwakste leerlingen willekeurig in twee groepen te verdelen, en dan de ene groep de nieuwe methode laten volgen en de andere groep niet. Die gebruiken we als testgroep. Dankzij het regressie-effect zullen beide groepen er na afloop ongetwijfeld op vooruit zijn gegaan, maar nu valt tenminste te meten of de ene groep het beter doet dan de andere) |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OPGAVEN | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||