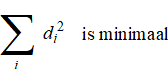|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Woord vooraf; Bij het bekijken van puntenwolken tot nu toe was het niet duidelijk (of maakte het niet uit) wat we op de x-as zetten, en wat op de y-as. Als je de assen zou omdraaien bleven de vormen van de puntenwolken gelijk; ze werden alleen gespiegeld in de lijn y = x. Nu gaat dat veranderen..... Vanaf nu gaan we ervan uit, als x en y van elkaar afhangen, dat x de oorzaak is, en y het gevolg. Dus de grootte van x "veroorzaakt" de grootte van y. Als je dat doet, dan spreken we van regressie van x op y. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| (Wees gerust: later zullen we ook andere varianten bekijken). | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1. Residuen. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De regressielijn die we berekenen geeft de
lijn die het best "past" bij onze meetgegevens. Maar wat wordt nou
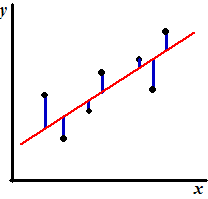
bedoeld met "best past" ??? Als we een regressielijn hebben gevonden, dan geeft die lijn aan welke y-waarden er het best (theoretisch) zouden passen bij de x-waarden. Maar de gemeten punten wijken natuurlijk af van die ideale lijn. Omdat we x als oorzaak en y als gevolg nemen is de afwijking van elk punt gelijk aan de lengte van de verticale blauwe lijnstukjes hiernaast. Hoe ver de gemeten y van de "best passende" y afligt. Die lengtes heten de residuen. Het residu van punt i noemen we di. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als je je GR de beste
regressielijn laat uitrekenen, bepaalt hij ook alle residuen di.
Die kun je vinden bij 2nd LIST 7:RESID Je kunt ze, als je dat leuk vindt, bijvoorbeeld in L3 zetten door in te toetsen: 2nd LIST 7:RESID STO 2nd L3 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Die residuen gaan we gebruiken om de "beste lijn" te vinden. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2. Kleinste Kwadraten. | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De methode van de kleinste kwadraten zegt nu,
dat voor de beste lijn geldt dat de som van "alle residuen in het
kwadraat" minimaal moet zijn:
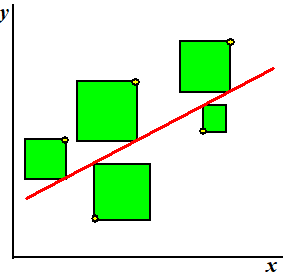
Het betekent eigenlijk dat je de rode lijn zó moet kiezen dat de totale oppervlakte van de groene vierkanten in de figuur hiernaast minimaal moet zijn. Dus afwijkingen verder van de lijn af tellen zwaarder mee dan afwijkingen in de buurt van de lijn. |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Als we de regressielijn y = ax + b stellen, dan is de som van de kwadraten van de residuen minimaal als we kiezen: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Daarin is: | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
x̅ = xgemiddeld en
y̅
= ygemiddeld Δxi = xi - x̅ en Δyi = yi - y̅ |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Het bewijs daarvan kun je hiernaast vinden.
Twee verschillende bewijzen zelfs, wat wil je nog meer! Dan móet het wel kloppen!! Wat staat hier nou eigenlijk? De vergelijking voor b is eenvoudig te interpreteren. b = y̅ - ax̅ ⇒ y̅ = ax̅ + b en daar staat niets anders dan dat het punt (x̅, y̅) op de regressielijn ligt. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De vergelijking voor a is
lastiger te interpreteren. De noemer komt je misschien nog bekend voor........???? Daar staat de totale kwadratische afwijking van alle x-en ten opzichte van het gemiddelde. Dat lijkt nogal op de standaarddeviatie σx, vind je niet? Die was gelijk aan de wortel van de gemiddelde kwadratische afwijking. Dus σx2 (dat heette de variantie) is gelijk aan de gemiddelde kwadratische afwijking. Als het aantal metingen gelijk is aan n, dan is de totale kwadratische afwijking gelijk aan n • σx2 en dat is precies de noemer van de vergelijking voor a. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
De teller is net zoiets, alleen
dan niet de afwijkingen van x keer zichzelf, maar de afwijkingen
van x keer de afwijkingen van y. Het is een soort
"gecombineerde" variantie, en we noemen hem dan ook de Covariantie,
en gebruiken er het symbool
σxy
en de afkorting Cov(x,y) voor:
(in deze les kun je er
eventueel meer over lezen). |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Voorbeeld. Stel op algebraïsche wijze een vergelijking van de regressielijn op die bij de volgende tabel hoort. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| De gemiddelde x is 8,429
en de gemiddelde y is 5,143, dus het centrale punt is
(8.429, 5.143) Dat geeft de volgende tabel: |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| Dan is a = 50,589/149,714
≈ 0,34 en b =
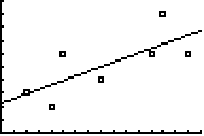
5,143 - 0,34 • 8,429 ≈ 2,24 De regressielijn heeft vergelijking y = 0,34x + 2,24 In de volgende tabel zie je hoe groot de voorspelde waarden van y zijn, en ook de residuen en hun kwadraat. Tenslotte staat ernaast een puntenwolk met de regressielijn erin. |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| OPGAVEN | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||